Amazon.com user reviews are a critical factor in increasing the sales for the giant retailer. The number of times, I have heard my wife say that she selected a particular product because of great user reviews, is far too high to count. These reviews can have significant credibility issues, though…In their great scholarly paper – Six degrees of reputation: The use and abuse of online review and recommendation systems – Shay David and Trevor Pinch point to some of the follies of user-generated reviews at Amazon.com:
Evidently, in many areas of cultural production user reviews are mushrooming as an alternative to traditional expert reviews. If there was any doubt, it has long ago been established that reviews and recommender systems play a determining role in consumer purchasing (an early review is available in Resnick and Varian, 1997) and recent qualitative research adds weight to the claim that these review systems have causal and positive effects on sales; to nobody’s surprise, books with more and better reviews are shown to sell better (Chevalier and Mayzlin, 2004). With people in the culture industries increasingly realizing this truism, many of the reviews are thus positively biased and it becomes very hard to distinguish the ‘objective’ quality of the reviews. In addition, due to the large variance in the quality of the reviews, and the varied agendas of the reviewers, user input too often becomes untrustworthy leaving the consumers with little ability to gauge an item’s actual quality. Do we live in a cultural Lake Wobegon where “all the books are above average?” (to paraphrase Keillor, 1985) Is there a way to review the reviewers, to guard the guards? As will be discussed in details below, emerging systems like the one employed on sites like Amazon.com (2005) suggest that there are ways to try to solve this bias problem by offering a tiered reputation management system which offers a set of checks and balances. But these new options also bring with them new problems as the participants adjust to what is at stake in this new economy of reputation.
They offer examples with links to amazon.com reviews:
This instance concerned one of Pinch’s own books Analog Days: The Invention and Impact of the Moog Synthesizer (Pinch and Trocco, 2002). This book that chronicles the invention and early days of the electronic music synthesizer was well received by reviewers both offline and online, and the Amazon.com editors quote a review from the Library Journal that reads as follows:
… In this well–researched, entertaining, and immensely readable book, Pinch (science & technology, Cornell Univ.) and Trocco (Lesley Univ., U.K. [sic]) chronicle the synthesizer’s early, heady years, from the mid–1960s through the mid–1970s … . Throughout, their prose is engagingly anecdotal and accessible, and readers are never asked to wade through dense, technological jargon. Yet there are enough details to enlighten those trying to understand this multidisciplinary field of music, acoustics, physics, and electronics. Highly recommended. [link]
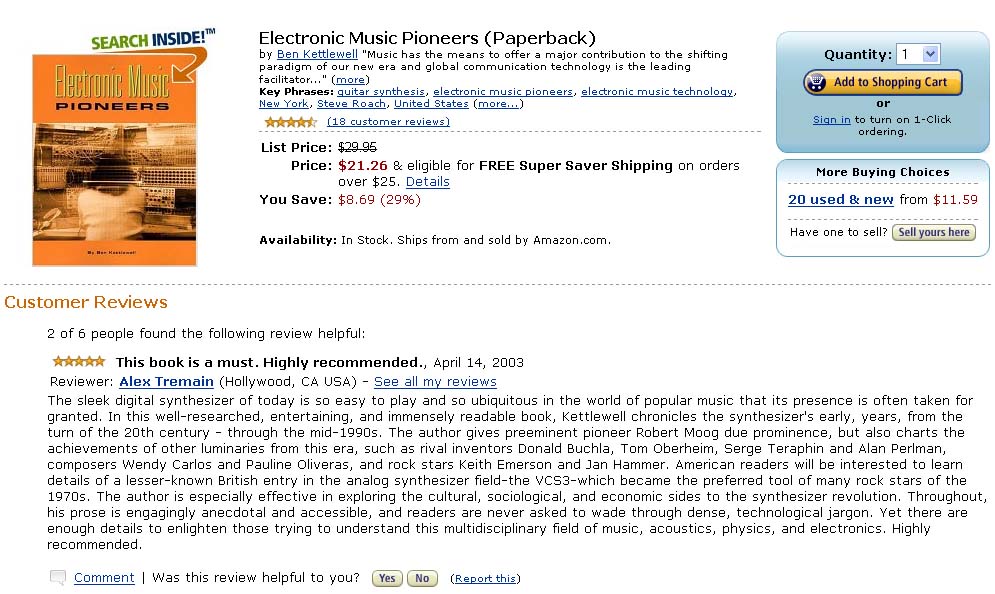
A similar (but distinctly different) book that had appeared earlier — Electronic Music Pioneers by Ben Kettlewell (Vallejo, Calif.: ProMusic Press, 2002) — received the following user review on Amazon.com on 15 April 2003:
This book is a must. Highly recommended., April 15, 2003 / Alex Tremain (Hollywood, CA USA)
… In this well–researched, entertaining, and immensely readable book, Kettlewell chronicles the synthesizer’s early, years, from the turn of the 20th century — through the mid–1990s … . Throughout, his prose is engagingly anecdotal and accessible, and readers are never asked to wade through dense, technological jargon. Yet there are enough details to enlighten those trying to understand this multidisciplinary field of music, acoustics, physics, and electronics. Highly recommended. [link]
The ‘similarity’, of course, is striking. The second review is simply a verbatim copy of the first one, replacing only the name of the authors and the period the book covers.
…
In another case a user reviewed several Tom Hanks/Meg Ryan movies. The user posted the same review for the movies Sleepless in Seattle and You’ve Got Mail. He found that each of those films was “a film about human relations, hope and second chances, but most importantly about trust, love, and inner strength.” [link link]
As we know, especially with the demands for producing one blockbuster after another, Hollywood movies are sometimes strikingly similar, and yet posting the same review for two different films suggests that the reviewer is interested less in accurate representation of the movie’s content or qualities and more in the sort of reputation and identity that he or she can build as someone who posts numerous reviews.



The authors point perverse incentives for different actors to game the review mechanisms:
- Self-plagiarize in order to write reviews quickly and to build up reviewer reputation (see examples with links above)
- Write unusually positive reviews to butter the publisher and the author in hope of landing a job as a full-time reviewer
- People with vested financial interest in the success of a product, take advantage of the cloak of anonymity and try to game the system by having family members etc. create positive reviews for their product and negative reviews for competing products
- Write reviews to see your name associated with a popular product. This can work as an ego boost for adolescents or even some adults
- Write reviews to promote other web sites or substitute products (example)
The authors find the problems mentioned above, based on their very limited analysis (due to the limitations of Amazon.com APIs), to effect about 1% of the reviews. I suspect, though, that a thorough analysis will reveal a significantly higher level of problem reviews.
So what can be done to deal with these issues? I believe that any system – both online and offline – has limitations that can be exploited by bad actors for personal benefit. Anybody remember the Armstrong Williams fiasco as an example of problems with offline systems? Still, as long as these systems are transparent and user expectations of how the systems work are properly managed, such systems can be valuable. Some of the specific things Amazon.com can do are:
- Provide more statistics about various issues with its user generated product reviews so as to properly set user expectations. They should point to all the various kinds of problems so that users take all the reviews on their site, with a pinch of salt. This, of course will be hard because doing this might reduce their revenue and potentially their influence, but in the long term pay off in terms of higher customer satisfaction.
- Be more receptive to user complaints and create a mechanism to penalize the people who try and game the system. At present they seem to be taking a completely hands off approach to policing the user reviews and as a result customers end up paying a price.
- Build up a more sophisticated notion of reputation which is based on reputation of users in other communities. Such a notion should include more elements then just the number of reviews a person has entered
- Build up a more sophisticated meta-moderation system like the one built by Slashdot.
This is not a simple problem but one Amazon.com should tackle to maintain long-term trust relationship with their users.



