There have been some new identity verification services trying to bring some order to the wild world of Internet.

You can read my take over on the Read/WriteWeb (Thanks Richard, for the great job editing and laying out the piece!).
There have been some new identity verification services trying to bring some order to the wild world of Internet.
You can read my take over on the Read/WriteWeb (Thanks Richard, for the great job editing and laying out the piece!).
Charlene Li of Forrester has an interesting report in which she tries to calculate the ROI (return on investment) for business blogging. Unfortunately the report is only available to paying customers but she lays out the model in a blog post:
Based on the model she has a comprehensive formula (I could not see it as the link is broken) that calculates the ROI. Charlene cites the example below as the kind of calculations she has in mind:
Let’s take for example the FastLane blog. One of the key goals of that blog was “to share information about its products and to start a dialogue between GM leaders and customers”. So a key metric would be to see how many times customers wrote a comment. FastLane has about 100 people commenting on the blog each month, which is equivalent to gaining customer insight on products and brands from a traditional focus group. We estimated that the value of this was equivalent to running a focus group every month at the cost of $15,000 a month, or $180,000 a year. Voila – there’s the value of the blogging benefit laid out in black and white.
I think the model she presents is a very useful way to quantify potential benefits, although, I am not sure I buy or will be swayed by specific calculations like the one above. The reason is that blogging opens up a new channel for customer interaction, which has its own unique dynamic. Comparing it to existing business activities like focus groups is problematic. E.g. with focus groups each participant is carefully selected whereas blog commenters are self selected web-savvy individuals.
The bottom line is that a CEO has to see the value of engaging customers in a conversation. I am not sure such calculations can help sway them as there are so many ways to poke holes in any such calculation. Another, more easy to establish, thing here could be to try and establish the costs associated with blogging. If the costs associated with blogging are not very high (I don’t think they should be), then the c-level exec’s will be more willing to take the plunge. I bet, another issue holding business blogging back, is that a number of c-level execs don’t fancy themselves as writers. As such, easy tools for video/audio blogging would enable them to take the leap much more easily.
More coverage on the topic is here.
Citizendium, is the new Wiki project, started by Larry Sanger, one of the co-founders of Wikipedia. They define the project as follows:
The Citizendium (sit-ih-ZEN-dee-um), a “citizens’ compendium of everything,” is an experimental new wiki project. The project, started by a founder of Wikipedia, aims to improve on the Wikipedia model by adding “gentle expert oversight” and requiring contributors to use their real names. It has taken on a life of its own and will, perhaps, become the flagship of a new set of responsibly-managed free knowledge projects. We avoid calling it an “encyclopedia” until the project’s editors feel comfortable putting their reputations behind this description.
With the new rules about the editors having to use their real name and with “gentle oversight”, Citizendium is trying to ensure that the community members have the right incentives. I guess the hope is that if people identifying themselves with their real names, they are less likely to vandalize or edit content for short term gratifications. The goal is to avoid cases like the one Stephen Colbert caused, when he talked about Wikipedia in one of his shows.
This is a noble goal and these new policies will no doubt help create a better community environment. The question, though, still remains about how Citizendium will ensure that all editors indeed use their real name while editing content. Right now they seem to be asking for individuals to use their real name as a part of their user agreement, but what is somebody still uses a fake name? I am sure if the Citizendium generates enough credible content, there are going to be incentives for people to use fake identities to edit content. One way could be to heap shame and scorn on any user breaking the terms of service but again if somebody does break their terms of service, how are they going to know what the real identity of the person is? Also, if they get enough critical mass, I am sure they will be open to attacks from payperpost like services intent on modifying certain content for financial gain.
So overall, I think this is a step in the right direction, I am not sure this is going to be enough to generate a 100% reliable body of knowledge. Let’s see how it develops.
I have been thinking about the differences in teenage and adult behavior in the sphere or creating and managing identities.

You can read my take over on the Read/WriteWeb (Thanks Richard, for the great job editing and laying out the piece!).
(For those of you, who haven’t seen the “Matrix” movies, Agent Smith was one of the protagonists of Neo. His special ability, after a mutation, was that he could create as many copies of himself as he liked. Also, you really need to watch the Matrix movies…I promise they’ll blow your mind.)
Bill Thompson, the regular columnist at BBC had an interesting piece about how young people use identities in social media.
…young people who forget their MySpace logins are just as likely to make a new account as fret over their lost friends or painstakingly constructed homepage decorations.
Recent work by US-based social media researcher Danah Boyd, one of the more astute observers of network behaviour, indicates that it is a more general attitude.
Her observations of young net users have led her to believe that “many teens are content (if not happy) to start over with most of their accounts in most places”, and she has noted that for young people an online profile is “not seen as something to build an extensive identity around, but something to use to talk to friends in the moment”.
Now this is very different from what I do. I have had the same myYahoo account for 7 years and have only made minor tweaks to the layout over that period. I hate losing access to an account that I created, as I think I am losing a part of myself by abandoning an account. As such, I try and get the same login name and password for all my accounts, to ensure that I can remember and maintain access to them.
…but perhaps teenagers, experimenting with their identity in relationships, clothing styles and all other aspects of life are simply extending this playfulness to the virtual realm.
Not all young users are casual about their online identity, of course, and Boyd is at pains to point out that many young people invest heavily in aspects of their online activities. However, the willingness to abandon a profile as a work-in-progress and start over is definitely something I’ve observed in my children and their friends.
This approach to online identity has a number of implications for anyone trying to understand the way the internet is growing, and also carries an important lesson for those trying to build services or make money out of them.
One positive aspect is that it will make it harder to pin online activity onto a real person, since accounts that are created and quickly discarded will contain fewer identifying details.
…
More importantly, this casualness clearly renders any statistics about the number of signed-up users effectively meaningless, and this could be a big problem for the sites themselves as companies vie for investment and point to sign-ups as an indicator of popularity and future success.
Commentator Clay Shirky has been waging a campaign against the sloppy journalism of those who quote Linden Labs figures for Second Life “residents”. He points out that many happily accept the headline figure of two million users without considering that only 36,000 of those are paid-for accounts while a high but indeterminate proportion of the remainder are inactive, set up for free by people who tried out the service and then moved on.
It is the same with MySpace, Bebo or any of the other social sites, of course, and shows how poor we are at measuring what really goes on online.
Websites, having struggled for years to adapt to the idea of the pageview instead of the server request as the key measure of site activity, are now building interactive pages that occupy user attention and time but don’t generate hits or page views – and they don’t know how to measure this usage. Now it seems that the millions of signups on MySpace, Bebo and the other social network sites could be the same set of forgetful teenagers coming back again.
And again.
This is an interesting observation and adds another argument to the need for better metrics to measure the value of online interactions. We have provided some ideas on the topic here, here and here. Danah Boyd, a PhD student at UC Berkely, explains this phenomenon as follows:
Adults often worry about the amount of time that youth spend online, arguing that the digital does not replace the physical. Most teens would agree. It is not the technology that encourages youth to spend time online – it’s the lack of mobility and access to youth space where they can hang out uninterrupted.
…
Teens have increasingly less access to public space. Classic 1950s hang out locations like the roller rink and burger joint are disappearing while malls and 7/11s are banning teens unaccompanied by parents. Hanging out around the neighborhood or in the woods has been deemed unsafe for fear of predators, drug dealers and abductors. Teens who go home after school while their parents are still working are expected to stay home and teens are mostly allowed to only gather at friends’ homes when their parents are present.
Additionally, structured activities in controlled spaces are on the rise. After school activities, sports, and jobs are typical across all socio-economic classes and many teens are in controlled spaces from dawn till dusk. They are running ragged without any time to simply chill amongst friends.
By going virtual, digital technologies allow youth to (re)create private and public youth space while physically in controlled spaces. IM serves as a private space while MySpace provide a public component. Online, youth can build the environments that support youth socialization.
So multiple throw away identities is another manifestation of teenagers experimenting with new looks etc. Another question that comes to mind …Is the phenomenon of throwaway identities only limited to teenagers? One place to look for answer is the blogosphere. On serious blogs, commenters can leave comments under any name they like. Now I have always used my own name while leaving a comment. But does anybody have stats on how many people use fake or context sensitive names (like using a name ILOVEAPPLE while leaving a comment positive to Apple) ? My guess is that the use of fake identities is a lot less prevalent in serious blogosphere compared to other teenage oriented social media.
I would imagine that as these teenagers mature and settle on an identity, they are comfortable with, they will focus on building their reputation around that identity. Now, a lack of a mechanism by which users in blogosphere and other social media can build a reputation around their identities, might be contributing to proliferation of these throwaway identities. May be, all we are lacking are incentives to participants in online social media, to maintain the same identity. What do you think?
This Tuesday, I was at the NewTechMeetup, where I saw a presentation from Robert Chea, Founder and COO of PowerReviews.
![]()
You can read my review of the startup over on the Read/WriteWeb (Thanks, Richard MacManus, for the opportunity!).
I just finished reading Malcom Gladwell’s wonderful book – The Tipping Point. The book talks about how and why, word-of-mouth epidemics, spread. There are lot of interesting studies and data points, related to human behavior, referred to in the book. I wonder why business schools don’t teach this subject in more detail. This book is absolutely essential reading for any web 2.0 startup.
At its core, the book makes a very interesting and persuasive case for the inherent social and context dependent nature of human beings. One piece, I really found fascinating relates to the Rule of 150, which talks about the size of effective groups. For those of you who haven’t read the book, the Rule of 150 states that the size of an effective social network is limited to 150 members. It seems that the human mind is unable to maintain effective relationships with members in groups larger than 150 people. The interesting thing seems to be that if the number of people in a group increases beyond 150, the deterioration in group effectiveness is not gradual but sudden. Malcom Gladwell quotes S.l. Washburn for the rationale:
Most of human evolution took place before the advent of agriculture when men lived in small groups, on a face to face basis. As a result human biology has evolved as an adaptive mechanism to conditions that have largely ceased to exist. Man evolved to feel strongly about few people, short distances and relatively brief intervals of time; and these are still the dimensions of life that are important to him.
This is very interesting… I wonder how the rule of 150 applies to online communities. Does it mean, on-line communities, that free participants from the limitations of geography, are somehow contrary to inherent human nature? How can one apply the rule of 150 to on-line communities? My guess is that the rule of 150 very much applies to on-line communities. Still, there is an interesting tension between the technology that makes it really easy to communicate with a wider set of people, and the waning effectiveness of that communication, as one reaches a wider audience. Applying this concept to blogosphere, maybe what a blogger should do, is give up the ambition of greater reach in favor of improved richness with a few people.
Another important point in the book relates to the power of the context. Malcom Gladwell uses a number of interesting studies and examples to make a strong case that human behavior is dependent on context. This means that instead of individual behavior being predestined based on character, a change in context can make people behave differently. So, a change in context, can make can make a docile individual, violent, a non-smoker, smoke, or an angry person, commit suicide etc.
It follows, that any technology that can provide context and identity on individuals, has the potential to dramatically change the participation levels in online communities.
Interesting piece in the WSJ about a start-up in redwood city, called Attributor.
Attributor analyzes the content of clients, who could range from individuals to big media companies, using a technique known as “digital fingerprinting,” which determines unique and identifying characteristics of content. It uses these digital fingerprints to search its index of the Web for the content. The company claims to be able to spot a customer’s content based on the appearance of as little as a few sentences of text or a few seconds of audio or video. It will provide customers with alerts and a dashboard of identified uses of their content on the Web and the context in which it is used.
The company is looking to ensure that all content reproduction or other uses are properly attributed and paid for. This sounds fantastic…although a bit hard to believe. I guess the content fingerprint is based on analysis of each piece of content and match is based on matching unattributed pieces to the original pieces via a search. What happens if the somebody just modifies a verb in the unattributed content? Would Attributor be able to catch that? May be they just do a statistical analysis of the content? I am really curious to find out more.

Wouldn’t a writer fingerprint be a better and more workable idea? I can imagine a writer having a fingerprint in terms of favorite words, syntax etc. Such a system will be able to handle situation such as one being discussed by Valleywag and VentureBeat. Also such a system could be very useful in social media as a way to establish identity of a user.
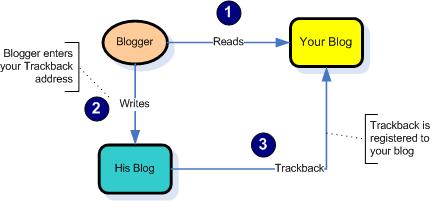
Recently, I got a trackback from a blog that seemed to have very little in common with my blog or the specific post I had. Upon further review, I found that the blog belonged to purveyors of a nasty little program, called DigBack. This is how they pitch the idea:
So your a blogger, and you want to get more people reading your blog posts. DigBack is the tool that will help you. When you make a blog post, that’s it, your post is published for someone to read if they happen to come visit your blog. So how do you get traffic immediately to your latest posts? Easy, with DigBack. DigBack will find and locate blog posts from other bloggers, and notify those blog posts that you have a blog post with similar content. This is all done through the trackback system. Say you write a blog post titled “Donald Rumsfeld Resigns”. DigBack will find posts from other blogs that have written something about Donald Rumsfeld’s resignation, and ping their blog post using the trackback protocol. Now there is a link on that other person’s post linking back to your article. People that visit that person’s article, can click the link to see what you have to say about Donal Rumsfeld. DigBack will continually look for similar posts all around the Internet on a continual basis.
Despite the spelling mistakes, it sounds promising…I looked further to find out how they establish whether two blogs are similar…Here is the relevant section from the FAQs:
How relevant are the blog posts DigBack finds?
Currently all posts found are based on the unique keywords you use in your post titles. The new version of DigBack expected to be released soon uses artificial intelligence to determine if found blog posts are similar to blog posts you write, making the system even more accurate.
…
No wonder, I got trackbacks that did not make any sense…Now my intention in discussing DigBack is not to encourage its use but rather discuss the limitations and potential abuses of the underlying Trackback system. Trackbacks were originally conceived and developed by Six Apart. The idea behind it was to enable distributed discussions that can be carried out on multiple blogs, with trackback providing the mechanism to cross-reference these different threads. For those of you who want to know more about trackbacks, Douglas Karr and Wikipedia have excellent descriptions:
The Trackback mechanism used to be a great way to carry out distributed conversations, but as the size of blogosphere has increased, this mechanism has come in for a lot of abuse from a number of bad agents. Some of these abuses have been:
The underlying weakness of the trackback system is that it treats all blogs the same despite their community behavior. So there is no quick way to a blogger receiving a trackback to quickly judge the quality of an incoming trackback. Also, if a blogger spams another blog, there are no penalties for such actions. What is needed is a better carrot and stick system such that it provides appropriate incentives to all bloggers to maintain the correct linking behavior. Some blog rating services like Authorati, the good blogs might help a little bit here but they need to provide better integration with the trackback system…Anybody up for developing such a system?
Check out the post at TrivialTV blog that details, via a graph, the relationship between inbound links and visitors to a site (Great data and thanks for making it public)…
In August 2006 I painstakingly harvested data to investigate the relationship between # of links and vistors/day and the effect of syndicates. I’ve only shared the data with a few friends so far, but one of them has been hounding me to share the plot with a wider audience. With Matthew Hurst’s post about Readers Or Links over at Data Mining today, I decided it’s worth going off-topic for a day. So here’s the plot:
I only included sites that used sitemeter with public data access and that were registered with technorati. Nearly 1800 different sites are represented in the figure.
In aggregate terms, the graph is a good proof that inbound links drive traffic (of course some links are more valuable then other). But it still does not answer the questions about influence…Which of the sites, listed in the graph above, have more influence. Check out this interesting post on the ebiquity blog:
Matt Hurst has a great example illustrating why measuring influence as inlinks (what Technorati does) is too simple. Here are two blogs, their inlink rank as computed by Technorati, their average daily visits as computed by Sitemeter, and the trend in visits over the past year.
blog rank visits trend Michelle Malkin ~19 ~120K steady pink is the new blog ~117 ~200K increasing As Matt pointed out, measuring readership with tools like sitemeter is problematic. As I write this I realize that I read Matt’s post through his feed in Bloglines, so his blogs will not have registered a visit.
Of course, it all depends on what you mean by influence which is mostly a function of why you are interested in it. For example, if your goal is to sell shoes, ads in “Pink” probably have more impact. If you want to push your new book “Taxes are evil” then Malkin’s blog is the way to go. So influence also has to be measured with respect to the community you want to influence.
Other factors that can determine influence are the kind of visitors that are coming to the site (meaning are these influential visitors or not), what these visitors are doing once they are on the site and how engaged are they … Check out our previous post on the subject that deals with how the engagement level of the users can be gauged using the attention data. Another measure of the influence of blogs can be the number and quality of comments. Of course without a universal measure of the quality of comments, relying on just the number of comments, could be very misleading. Bloggers can just turn off the spam filter and that will generate a huge number of bad comments and thereby game the system for judging influence. But with a common gauge of comment quality, the number of comments can be a useful measure of influence. Developing and popularizing a universal gauge for the quality of comments, is a tough nut to crack but its importance cannot be overstated. I am looking forward to more research (I am waiting for the paper that ebiquity guys mentioned) and new ideas on how best to measure influence…Indeed the future of online communities might depend on it.